
我们在上文介绍了知识图谱的多种数据来源,但是这些数据源中抽取的知识来源广泛,知识的质量可能良莠不齐,也可能存在数据重合的部分,所以需要对知识进行融合,将不同数据源的知识统一规范,形成高质量的知识库。在不同的文献中,知识融合可能有不同的叫法,如本体对齐,本体匹配,实体对齐等,本文统一称之为知识融合。
知识融合主要包含有三种类型:
第一种是同一个实体有多种不同的表达方式,例如鲁迅原名是周树人,字豫才,对于这些不同的名称都需要规约到同一个实体下。另
一种是同一种表达在不同的语境下可能指代的是不同的实体,即一词多义,例如“苹果”有可能是指美国苹果公司,也有可能是指水果。
第三种是跨语言的知识融合,同一个实体在不同的语言或地区可能有不同的命名,例如腾讯公司的英文是Tencent。
在实际工作中,知识融合是数据预处理不可或缺的一部分,知识融合的好坏直接决定了知识库的质量,也决定了知识图谱项目的成功与否。
最基本的知识融合方法是知识卡片融合,即上文提到的百科类网站infobox信息,不同的百科网站对于同一个实体的描述可能有差异,所以可以将同一个实体在不同的百科类网站中进行搜索查询,将查询信息合并成为一个归一化之后的知识卡片,即可完成知识融合。
但是对于绝大多数的知识融合而言并不会像知识卡片的融合这样简单,我们知道不同的本体实例是由他们所拥有的属性决定的,如果两个不同的实体,属性都是相同或者近似的,那么我们就可以根据一定的规则将实体进行融合。所以要判断实体是否是同一个实体,是实体的属性是否相似来判断,属性的相似度决定了实体的相似度。
知识融合的流程通常分为四步,分别是数据预处理、数据预分组、属性相似度计算和实体相似度计算。
数据预处理
将不同数据源的数据统一格式,例如去除标点符号,洗掉脏数据等,这一步通常需要人工进行,相关的方法可以参考前面章节的数据预处理部分。
数据预分组
这一步主要是为了加快知识融合的效率,降低计算的难度。如果不进行分组的话,那么后续的实体比较过程就需要庞大的计算量。常用的数据分类方法可以采用产品经理指定类型进行分组,也可以使用机器学习的方法进行无监督聚类分组或有监督的分类进行分组。
属性相似度计算
根据不同的数据类型,需要采用不同的方法。如果融合的数据对象是纯字符串类型的数据,可以使用编辑距离(levenshtein distance),这是一个度量两个字符串之间相似度的算法,指两个字符串之间,由字符串A转换到另一个字符串B所需要最少的插入、删除、替换等操作的次数,操作次数越少意味着两个词越相似。
如果要融合的是集合类型的数据,可以通过jaccard相似系数进行计算,公式如下:
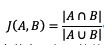
当两个集合A和B交集元素的个数在A与B的并集中所占比例,称之为jaccard系数,jaccard值越大说明相似度越高,如果完全一致的两个集合则相似度为1。类似的余弦相似度也可以用来计算集合类型的数据。
如果是整篇文档类型的数据,可以线通过TF-IDF算法找出文档的关键词,再通过余弦相似度计算关键词集合的相似度,以此判断文档的相似度。另外,使用词袋模型也可以用来计算文档的相似度,这两个方法我们会在后续章节详细讲解。
实体相似度计算
这是知识融合的第四步也是最后一步,常用的方法是聚类和聚合两种。聚类算法在之前的章节详细讲过K-means聚类,在计算实体相似度的时候,K-means聚类常常和Canopy聚类配合使用,Canpy聚类最大的特点是不需要事先指定K值。除了这两种聚类方法外,层次聚类和相关性聚类也可以用于实体相似度的计算。
另一种计算实体相似度的方法是采用聚合算法,根据属性相似度的结果计算出相似度的得分向量,然后根据机器学习的分类算法,例如逻辑回归、决策树以及支持向量机等。
3. 实操案例:Protégé构建漫威英雄关系图谱知识图谱技术刚刚处于起步阶段,目前业内并没有一款通用的本体编辑工具,多数要进行知识图谱构建的项目,需要先开发一套知识图谱本体辑软件工具,然后再在这基础之上进行图谱的构建工作。
本章节的实操案例,我们将使用Protégé来进行,这是一款由斯坦福大学医学院生物信息研究中心基于Java语言开发的本体编辑和知识获取软件,主要用于语义网中本体的构建,虽然不支持多人协同编辑,但已经是目前比较成熟的开源知识图谱编辑工具,包含了整个图谱生成、可视化展现以及知识推理的过程。而且软件本身是开源的,所以可以基于源码对软件进行适当的改造,以符合公司项目需要。非常适合产品经理理解知识图谱的相关技术原理。Protégé的主界面如图所示。

首先,我们需要构建本体,当打开Protégé软件时会默认打开“Active Ontology”菜单栏,在该菜单下的“Ontology IRI”输入项中,会有一个默认的本体前缀名,我们可以把它改为自定义的名称,就像给变量设置变量名一样,这里我将其设置为“”,如图所示。
如果想要新建一个本体,点击File菜单栏下的New选项即可。

当我们构件好本体之后,点击“Entities”选项卡进行本体编辑,首先选择该选项卡下的“Classes”标签创建新的类。如图所示,在这个页面中,左侧是所有的类,用树形结构展示了类之间的对应关系,如果选中左侧的某个类,可以在右侧设置这个类的相关描述。我们会看到已经有了一个owl:Thing的类存在,这是系统默认的所有类的父类。

单击选中Thing,在其左上角点击图标可以创建子类,在弹出的菜单中的Name输入项中设置子类的名称,这里我们输入“电影”,然后点击确定。接着选中新创建的电影类,并点击中间的图标创建创建兄弟类,兄弟类的名称我们设置为“人物”,并在人物类下再构建两个子类,分别命名为“男人”和“女人”这样就完成了类的创建。
当然,也可以在相关的类上单击鼠标右键,在弹出的菜单中选择“Add subclass”以及“Add sibling class”来创建子类和兄弟类,效果和点击按钮是一样的。
如果想要删除某个类,只需要选中类之后点击最右侧的图标即可删除。
3.3 设置类之间的关系我们创建四个类,现在可以对这4个类设置一些属性了,在本例中,男人与女人是互斥关系,一个人的实例只能是男人或女人中的某一个,所以我们可以使用“Disjoint With”属性来进行描述。
选中女人类,然后点击右侧的“Disjoint With”属性右侧的加号按钮,在弹出的菜单中选择男人类,然后点击确定即可完成一个关系的创建。同样的操作我们可以设置人物和电影也为互斥的类,如图所示。










